// This is Arrays.binarySearch(), but doesn't do any argument validation. staticintbinarySearch(int[] array, int size, int value) { intlo=0; inthi= size - 1;
while (lo <= hi) { finalintmid= (lo + hi) >>> 1; finalintmidVal= array[mid];
if (midVal < value) { lo = mid + 1; } elseif (midVal > value) { hi = mid - 1; } else { return mid; // value found } } return ~lo; // value not present }
staticintbinarySearch(long[] array, int size, long value) { intlo=0; inthi= size - 1;
while (lo <= hi) { finalintmid= (lo + hi) >>> 1; finallongmidVal= array[mid];
if (midVal < value) { lo = mid + 1; } elseif (midVal > value) { hi = mid - 1; } else { return mid; // value found } } return ~lo; // value not present } }
首先这个方法写在ContainerHelpers这个工具类中,这个类只有这一个方法的两种重载。基本代码是正宗的二分查找写法,而重要区别在于最后当查找失败时返回的值:~lo。一般二分查找会返回-1这样没有意义的负值,表示元素不存在,但这里返回的却是最后一次查找时得到的low值取反。这是非常优秀的设计。这也是一个负值,但为什么标新立异,要返回这样的值呢?这是因为,sparseArray通过二分查找寻找key,而二分查找的前提是数组有序。当找不到一个key时,证明我们需要在mKeys数组中插入这个key,且其插入的位置应该满足升序。又因为,当二分查找失败时,最后应该有low = high = mid,而这个low正是理想的插入位置,在这个位置上插入新的key,数组整体依然保持有序。所以我们希望知道这个位置的值,以方便下次插入。但又需要提醒调用者查找是失败的(即需要负值这样的特殊值),所以最终就对low取反并返回。这样,我们既能知道二分查找失败,当前key不存在,又能知道应该插入的理想位置,一举两得。
/** * Gets the Object mapped from the specified key, or the specified Object * if no such mapping has been made. */ @SuppressWarnings("unchecked") public E get(int key, E valueIfKeyNotFound) { inti= ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) { return valueIfKeyNotFound; } else { return (E) mValues[i]; } }
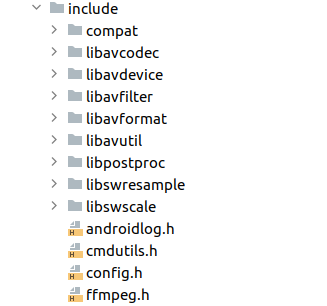
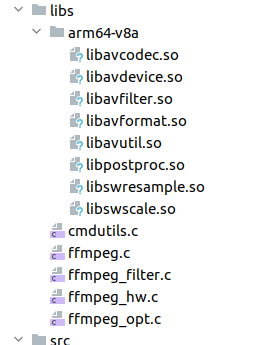
其中cmake项是配置CMakeLists的路径和CMake的版本。 默认情况下,Gradle(无论是通过 Android Studio 使用,还是从命令行使用)会针对所有非弃用 ABI 进行构建。要限制应用支持的 ABI 集,请使用 abiFilters。如这里我填入了arm64-v8a,正是对应了编译FFmpeg时指定的目标CPU和架构。如果这里不设置abiFilter的话,之后构建app会出现问题。
The error you’re getting means that ndk-build is trying to use your .so file while compiling your module for an incompatible target. Android supports several cpu architectures (armeabi, armeabi-v7a, arm64-v8a, x86, x86_64, mips, mips64). You can choose which one you want to support using the APP_ABI variable from Application.mk. If you set it to all, ndk-build will try to use this .so file you’re referencing for each of these architectures, but this cannot work. Your .so file must have been compiled for Android platforms, and you need to have a different version of it for each architecture you’re supporting. You can give a dynamic reference to the right .so file, such as LOCAL_SRC_FILES := $(TARGET_ARCH_ABI)/libslabhidtouart.so so it looks for your .so file under armeabi-v7a folder when compiling for armeabi-v7a, under x86 for x86, etc. Of course you need to provide these .so files. If you can’t get .so files for all the supported architectures, you’ll have to restrict your APP_ABI to the architectures of the .so file you have. You can determine the architecture your .so file has been compiled for using readelf.
if (!sws) { av_log(nullptr, AV_LOG_INFO, "Cannot create sws context.\n"); }
// open writing stream of output file outputFile = fopen(outputPath, "wb"); if (!outputFile) { av_log(nullptr, AV_LOG_ERROR, "Failed to open output file!\n"); }
...
if (!x264Param) delete x264Param; x264Param = newx264_param_t; int ret = x264_param_default_preset(x264Param, "fast", "zerolatency"); if (ret < 0) { av_log(nullptr, AV_LOG_ERROR, "Failed to set preset parameter!\n"); }
...
ret = x264_param_apply_profile(x264Param, x264_profile_names[1]); if (ret < 0) { av_log(nullptr, AV_LOG_ERROR, "Failed to apply main profile!\n"); }
encoder = x264_encoder_open(x264Param); if(!encoder) { av_log(nullptr, AV_LOG_ERROR, "Failed to open x264 encoder!\n"); }
// Write headers to file int header_size = x264_encoder_headers(encoder, &nals, &nalCount); if(header_size < 0) { av_log(nullptr, AV_LOG_ERROR, "Error when calling x264_encoder_headers()!\n"); } // outputStream << nals[0].p_payload; if (!fwrite(nals[0].p_payload, sizeof(uint8_t), header_size, outputFile)) { av_log(nullptr, AV_LOG_ERROR, "Failed to write header!\n"); }
必要的内存释放代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
X264Encoder::~X264Encoder() { if (encoder) { x264_picture_clean(&inFrame); x264_encoder_close(encoder); encoder = nullptr; } if (outputFile) { fclose(outputFile); outputFile = nullptr; } if (sws) { sws_freeContext(sws); sws = nullptr; } delete mbQp; }
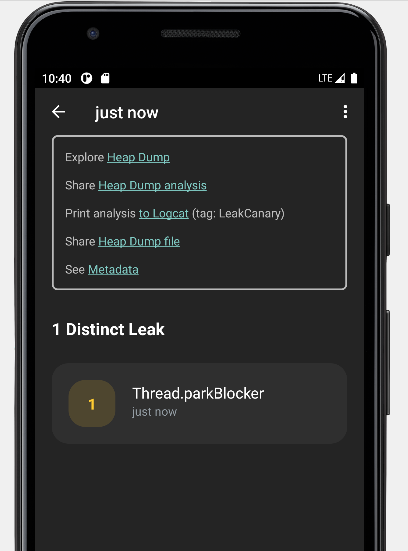
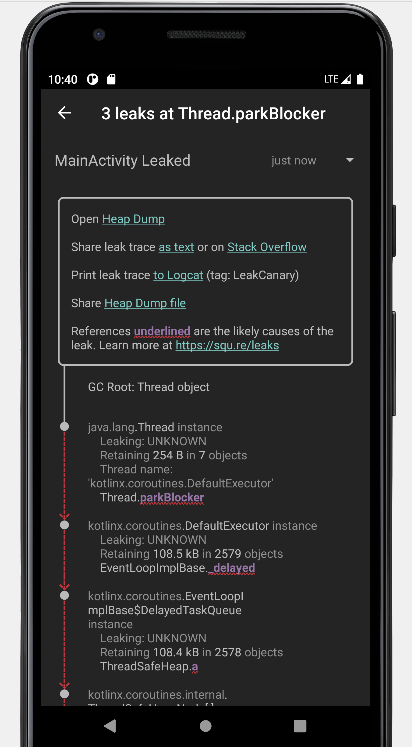
A Library Leak is a leak caused by a known bug in 3rd party code that you do not have control over. See https://square.github.io/leakcanary/fundamentals-how-leakcanary-works/#4-categorizing-leaks ==================================== 0 UNREACHABLE OBJECTS
An unreachable object is still in memory but LeakCanary could not find a strong reference path from GC roots. ==================================== METADATA
Please include this in bug reports and Stack Overflow questions.
Build.VERSION.SDK_INT: 30 Build.MANUFACTURER: unknown LeakCanary version: 2.9.1 App process name: com.eynnzerr.avplayer Class count: 19677 Instance count: 104943 Primitive array count: 86281 Object array count: 17593 Thread count: 20 Heap total bytes: 16092598 Bitmap count: 0 Bitmap total bytes: 0 Large bitmap count: 0 Large bitmap total bytes: 0 Stats: LruCache[maxSize=3000,hits=35774,misses=78728,hitRate=31%] RandomAccess[bytes=3855083,reads=78728,travel=23243159115,range=18698859,size=24675970] Heap dump reason: user request Analysis duration: 3073 ms Heap dump file path: /storage/emulated/0/Download/leakcanary-com.eynnzerr.avplayer/2022-10-27_22-39-44_274.hprof Heap dump timestamp: 1666881589949 Heap dump duration: 1291 ms
// 如果已经安装过了则抛异常 if (isInstalled) { throw IllegalStateException( "AppWatcher already installed, see exception cause for prior install call", installCause ) }
// 检查输入参数 retainedDelayMillis 的合法性 check(retainedDelayMillis >= 0) { "retainedDelayMillis $retainedDelayMillis must be at least 0 ms" } this.retainedDelayMillis = retainedDelayMillis
// debug时开启日志 if (application.isDebuggableBuild) { LogcatSharkLog.install() }
// Requires AppWatcher.objectWatcher to be set LeakCanaryDelegate.loadLeakCanary(application)
// 为传入待注册的 InstallableWatcher 一一调用注册 watchersToInstall.forEach { it.install() } // Only install after we're fully done with init. installCause = RuntimeException("manualInstall() first called here") }
val durationMillis: Long if (currentEventUniqueId == null) { currentEventUniqueId = UUID.randomUUID().toString() } try { InternalLeakCanary.sendEvent(DumpingHeap(currentEventUniqueId!!))
if (heapDumpFile == null) { throw RuntimeException("Could not create heap dump file") } saveResourceIdNamesToMemory() val heapDumpUptimeMillis = SystemClock.uptimeMillis() KeyedWeakReference.heapDumpUptimeMillis = heapDumpUptimeMillis durationMillis = measureDurationMillis { // 关键:执行dump hprof到指定文件 configProvider().heapDumper.dumpHeap(heapDumpFile)
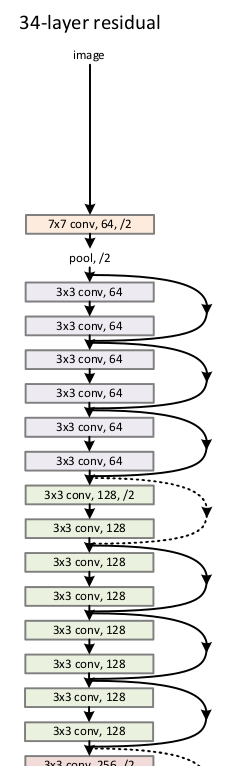
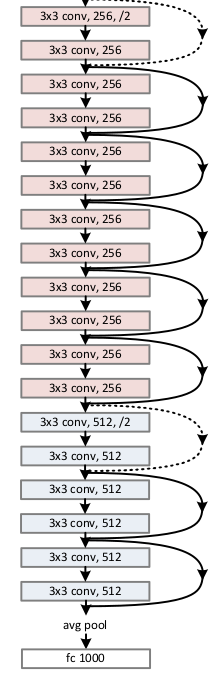
defresnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet: r"""ResNet-34 model from `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress, **kwargs)
def__init__(self, ch_in, num_classes=2): super().__init__() self.pool = nn.AvgPool2d(kernel_size=5, stride=3) self.conv = ReluConv(ch_in=ch_in, ch_out=128, kernel_size=1, stride=1) self.fc1 = nn.Linear(in_features=2048, out_features=1024) # input is N x 128 x 4 x 4 self.fc2 = nn.Linear(in_features=1024, out_features=num_classes)
defforward(self, x): x = self.pool(x) x = self.conv(x) x = torch.flatten(x, 1) # as input of fc layer x = self.fc1(x) x = F.relu(x) x = F.dropout(x, 0.7, training=self.training) x = self.fc2(x) return x
staticclassEntryextendsWeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */ Object value; Entry(ThreadLocal<?> k, Object v) { super(k); value = v; } }
注:Byte, Short, Int, Long 还具有对应无符号类型:UByte, UShort, UInt, ULong。
字面量写法:
1 2 3 4 5 6 7
val intNum = 100// 默认推断为 Int val longNum = 100L// L 后缀表示 Long val floatNum = 3.14f// f 后缀表示 Float val doubleNum = 3.14// 默认推断为 Double val hexNum = 0xFF// 十六进制 val binaryNum = 0b1010// 二进制 val readable = 1_000_000// 支持下划线分隔,提升可读性
显式类型转换: ⚠️Kotlin 不支持隐式类型转换,必须显式调用转换函数:
1 2 3
val i: Int = 100 val l: Long = i.toLong() // ✅ 正确 // val l: Long = i // ❌ 编译错误
1.1.1 Number 类
以上数值类型都有一个共同的父类:Number,这是一个抽象类,并定义了一系列显示类型转换函数:
1 2 3 4 5 6 7 8 9
publicabstractclassNumber { publicabstractfuntoDouble(): Double publicabstractfuntoFloat(): Float publicabstractfuntoLong(): Long publicabstractfuntoInt(): Int publicabstractfuntoChar(): Char// Deprecated publicabstractfuntoShort(): Short publicabstractfuntoByte(): Byte }
通过继承 Number类并实现 Comparable接口,派生出以上数值类型。
1.2 字符与字符串
Char 表示单个字符(16-bit Unicode),用单引号包裹;字符串用双引号或三引号表示:
1 2 3 4 5 6
val letter: Char = 'A' val str = "Hello, Kotlin" val multiLine = """ 这是多行字符串 保留原始格式 """.trimIndent()
val char: Char = 'A' val i: Int = char.code // Code of a Char is the value it was constructed with, and the UTF-16 code unit corresponding to this Char. val l: Long = char.code.toLong() val c: Char = i.toChar() // significant 16 bits of this Int value. val d: Char = i.digitToChar() // decimal digit
Kotlin 支持字符串模板,这在构造特定字符串以及日志打印等场景都非常好用:
1 2 3
val name = "World" println("Hello, $name!") // 简单变量 println("长度是 ${name.length}") // 表达式
Kotlin String 还有更多值得说道的知识点,在此先略过,之后另写一篇博客来详细探讨。
1.3 布尔类型与数组
1 2 3 4 5 6 7
val isKotlinFun: Boolean = true
// 泛型数组 val arr = arrayOf(1, 2, 3)
// 原始类型数组(避免装箱开销) val intArr = intArrayOf(1, 2, 3)
二、数值字面量的实现机制
既然 Kotlin 中 Int 是一个类,为什么 val x = 1 不需要写成 val x = Int(1) 这样的构造函数形式?
2.1 字面量是语言级别的语法糖
数值字面量是 Kotlin 语言规范直接支持的特殊语法,编译器看到 1 时,直接将其识别为 Int 类型的字面量常量,不需要经过任何构造函数调用。
1 2
val x = 1// 字面量语法,编译器直接处理 val y = Int(1) // ❌ 编译错误!Int 没有公开构造函数
2.2 为什么 Int 没有构造函数?
Kotlin 的数值类型是特殊的内置类型,构造函数是私有的:
设计原因
说明
性能优化
编译器可以直接映射到 JVM 原始类型,无需真正的对象分配
语义清晰
1 就是 1,不需要 new Integer(1) 的冗余
防止滥用
避免 Int(someString) 这种容易出错的用法
2.3 编译过程示例
1 2 3 4 5 6 7 8
┌─────────────────────────────────────────────────────┐ │ Kotlin 源码 val x = 1 │ ├─────────────────────────────────────────────────────┤ │ 编译器理解 x 是 Int 类型,值为字面量 1 │ ├─────────────────────────────────────────────────────┤ │ 字节码输出 ICONST_1 (JVM 原始 int 指令) │ │ ISTORE x │ └─────────────────────────────────────────────────────┘