该篇内容为原博客博文,原上传于2021年11月27日。
一、前言 Docker是什么?
Docker takes away repetitive, mundane configuration tasks and is used throughout the development lifecycle for fast, easy and portable application development - desktop and cloud. Docker’s comprehensive end to end platform includes UIs, CLIs, APIs and security that are engineered to work together across the entire application delivery lifecycle.
Docker是一个用Go编写的开源工具,它可以将你的应用打包成一个标准格式的镜像,并且以容器的方式运行。Docker容器将一系列软件包装在一个完整的文件系统中,这个文件系统包含应用程序运行所需要的一切:代码、运行时工具、系统工具、系统依赖,几乎有任何可以安装在服务器上的东西。这些策略保证了容器内应用程序运行环境的稳定性,不会被容器外的系统环境所影响。

Docker容器的特点:
- 轻量: 在同一台宿主机上的容器将共享系统kernel,使得它们可以迅速启动而且占用较少的内存。镜像是以分层文件系统构造的,这可以让它们共享相同的文件,使得磁盘使用率和镜像下载速度都得到较大提高。
- 开放: Docker容器基于开放标准,使得其可以运行在各种主流Linux Distribution和Windows,以及Mac OS上。
- 安全: 容器将各个运行的应用程序相互隔离开来,给所有的应用程序提供了一层额外的安全防护。
容器和虚拟机相比
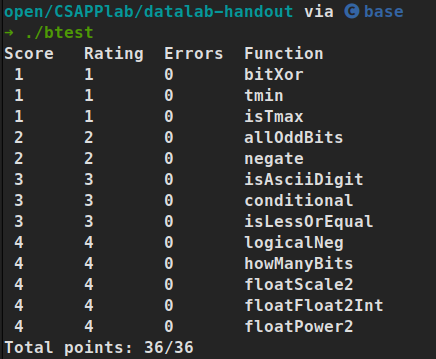
容器和虚拟机同样具有资源隔离和分配的功能,但由于其架构的不同,容器比虚拟机更加便捷和高效。
首先是犯下傲慢之罪的虚拟机,包含用户的程序,必要的函数库和整个客户操作系统,至少也需要占用好几个GB的空间。如图所示,除了使用Hypervisor技术对硬件设施进行虚拟化外,虚拟机还多一层guest OS。
而docker容器则是在docker engine的控制和驱动下,以用户态运行,并在宿主机上互相隔离。docker直接使用硬件资源和共享内核,不和任何基础设施绑定。
容器基本概念
我们还是先回顾一波docker中的基础概念。
| 名称 |
说明 |
| 镜像(Image) |
Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 centos8 就包含了完整的一套 CentOS 8 最小系统的 root 文件系统。 |
| 容器(Container) |
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。 |
| 仓库(Repository) |
仓库可看成一个代码控制中心,用来保存镜像。 |
| Docker 客户端(Client) |
Docker 客户端通过命令行或者其他工具使用 Docker SDK (https://docs.docker.com/develop/sdk/) 与 Docker 的守护进程通信。 |
| Docker 主机(Host) |
一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。 |
| Docker Registry |
Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。 |
二、docker的基本使用
以一个精简的UNIX工具箱busybox为例
docker pull busybox
从仓库拉取latest的busybox镜像
docker images
查看本地镜像
docker rmi -f busybox
强制删除busybox镜像
docker run -it ubuntu /bin/bash
从镜像生成一个容器,分配伪终端,并采用交互模式运行,且在进入容器后执行/bin/bash
docker ps
查看所有正在运行的容器,加参数-a还可以查看停运的容器
docker start busybox
启动停止运行的容器busybox
docker stop busybox
停止正在运行的容器busybox
docker restart busybox
重启容器busybox
docker kill busybox
杀死运行中的容器busybox
docker rm -f busybox
移除容器busybox
docker pause busybox
暂停容器中所有进程
docker unpause busybox
暂停后继续容器中所有进程
docker create busybox
创建一个容器但是不启动
docker exec -it busybox /bin/bash
在正在运行的容器中执行/bin/bash这个命令
这也是进入运行中容器的一种方法
and so on……
二、Docker实现原理探究
那么,docker是如何生成这样精简而健全的一个个容器的呢?今天,我们就来研究一波其中运用到的三个主要的功能:Linux namespace, cgroups, Union File System(UFS)。下面我们一一进行探讨。
Linux namespace
本来,不同的进程是共享同一份内核资源的。要做一个通俗的类比的话,如果说每个进程是单独的一个住户,那么内核资源就好比是小区里的公共场所,大家都可以使用,且使用情况对彼此都可见。而ns的作用,就是把这样的公共场所隔离开来。但这里的隔离,说的并不是将公共场所分成几部分,交给不同的进程,而是每个进程依然有原来一样大的公共场所,公共场所中的资源和变更情况只有他自己能看到。如果他在公共场所丢了一根烟头,则只有他自己知道,其他人(进程)是感知不到的。
Linux Namespace就是这样提供了一种内核级别隔离系统资源的方法,通过将系统的全局资源放在不同的Namespace中,来实现资源隔离的目的。不同Namespace的程序,可以享有一份独立的系统资源。
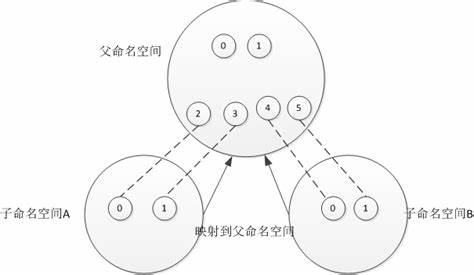
namespace的API有如下3个syscall:
- clone() 创建新进程,并根据传入的系统调用参数判断那些类型的namespace被创建,并且其子进程也会包含到这些namespace中。
- unshare() 将进程移出某个namespace。
- setns() 将进程加入某个namespace。
目前Linux中提供了六类系统资源的隔离机制,分别是:
- Mount: 隔离文件系统挂载点
- UTS: 隔离主机名和域名信息
- IPC: 隔离进程间通信
- PID: 隔离进程的ID
- Network: 隔离网络资源
- User: 隔离用户和用户组的ID
- Cgroup: 隔离cgroup根目录(最新,尚未被docker采用)
下面一一解释他们的作用:
Mount namespace
Mount Namespace用来隔离各个进程看到的挂载点视图。不同namespace的进程,看到的文件系统层次是不同的。在mount namespace中调用mount, umount等命令只会影响当前namespace内的文件系统,而对全局的文件系统是没有影响的。(事实上,docker容器内的挂载情况确实和宿主机不同。)
Mount Namespace是linux第一个实现的namespace类型,因而它的syscall参数比较特殊,是NEWNS。
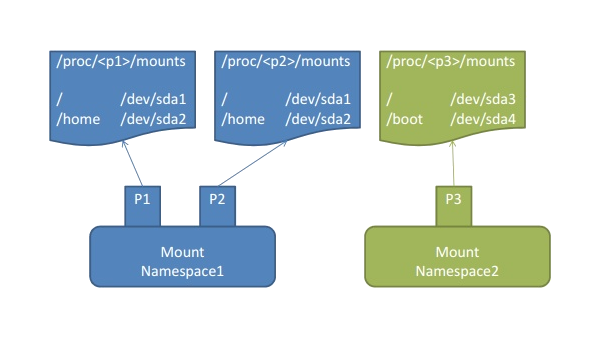
但是有一点需要注意:有些时候,Mount Namespace其实并不能真正隔离挂载信息!这是因为linux中还存在一种名为Shared Subtree的机制!
引入该机制是为了消除mount ns带来的不便,比如系统新增一块磁盘,我希望所有的NS都感知到新挂载的这块磁盘,那么如果NS 之间是完全隔离的,就需要每个都执行一次挂载操作,这是非常不变的,shared subtree保证了不同的NS 之间可以共享挂载信息。
共享子树有两大核心:peer group和propagate type。
- peer group
表示了一个或多个挂载点的集合,下面两种情况属于统一group:
通过–bind操作挂载的源挂载点和目标挂载点(前提是源目录是个挂载点)
生成新mount ns时,复制过去的挂载点之间同在一个group
- propagate type(传播属性)
这是mount点的属性,其常见值有:
- MS_SHARED 该挂载点的删除操作、该挂载点下子挂载点的新增和删除操作都会同步到同一group中的其他mount点,且其他同group的mount点的操作也会同步到该mount点
- MS_PRIVATE 与1相反,不会将自己的信息共享出去,也不接受其他点的共享,从而实现真正的隔离
- MS_SLAVE 单向的共享,自己的更新不会影响到他人,但是他人的操作会同步到自己
通过以下命令当前挂载点的传播属性:
cat /proc/self/mountinfo
可以发现所有进程默认情况下都是shared的。又因为通过系统调用clone出的namespace与父进程处在一个peer group下,所以会完全copy父进程的挂载点信息,因此子进程的挂载点也是shared。如果不注意到这点的话,创建的容器就不会真正隔绝挂载信息,且会引起一些不妙的后果。我们放在后面构建简单docker容器的实战中再说这个bug。
UTS namespace
UTS namespace主要用来nodename和domainname两个系统标识。也就是说,每个UTS Namespace被允许有自己的主机名(docker网络通信的重要基础之一)。
我们可以通过一个简单的Go语言demo来验证UTS namespace的作用:
func main() {
cmd := exec.Command("sh")//指定新进程的初始命令
cmd.SysProcAttr = &syscall.SysProcAttr {
CloneFlags: syscall.CLONE_NEWUTS,
}//设定系统调用属性
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr//设置标准输入输出
if err := cmd.Run(); err != nil {
log.Fatal(err)
}//运行命令和错误处理
}
执行代码,在启动的交互式环境里,先用echo $$输出一下当前进程的PID,再用pstree -pl查看进程树,找到父进程。由于在进程目录下的ns目录包含进程的namespace信息,其中uts就对应 UTS namespace的信息。且由于ns目录下的这些文件其实都是特殊的符号链接,所以需要用readlink读取其实际指向的内容,便可以知道其UTS namespace的inode号了。于是用readlink /proc/xxxxx/ns/uts比较ns的inode,可以验证他们不在同一个UTS Namespace中。
接着,执行hostname -b chenpeng,修改当前主机名。另外启动一个shell,使用hostname命令,会发现外部的hostname并未因内部的修改而改变,证明了UTS Namespace的作用。
其他namespace的作用可以类似地验证,接下来就主要介绍他们的作用即可。
IPC Namespace
用来隔离System V IPC和POSIX message queues。
PID Namespace
用来隔离进程ID。同样一个进程在不同的PID Namespace中可以拥有不同的PID。可以通过分别在宿主机和容器内执行ps -ef验证docker对这个namespace的运用。
User Namespace
用来隔离用户的用户组ID。也就是说,一个进程的User ID和Group ID在User Namespace内外可以是不同的。比如在宿主机上的以非root用户运行创建一个User Namespace,而在namespace里面这个用户被映射为root用户。这意味着,这个进程在User Namespace里拥有root权限,但在外面却没有。从Linux Kernel 3.8开始,非root进程也可以创建User Namespace并被映射成root。
Netwoek Namespace
用来隔离网络设备、IP地址端口等网络栈。可以让每个容器拥有自己独立的虚拟网络设备,且容器内的应用可以绑定到自己的端口,使得各个Namespace内的端口不会互相冲突。且在宿主机上搭建网桥后,可以很方便地实现容器间通信。此外,通过端口映射,可以使得不同容器上的应用使用相同的端口号。
Linux Cgroups
namespace技术可以帮助构建出的容器拥有自己与外部隔离的单独的空间,但Docker是如何限制每个容器所占空间的大小,从而保证它们不会相互争抢的呢?这就要运用Cgroups技术。
Linux Cgroups(Control Groups)提供了对一组进程及其将来子进程的资源限制、控制和统计的能力,这些资源包括CPU,内存,存储,网络等。通过Cgroups,可以方便地限制某个进程的资源占用,并且实时地监控进程和统计信息。
比如可以通过cgroup限制特定进程使用特定数目的cpu核数和特定大小的内存,如果资源超限的情况下,会被暂停或者杀掉。
- 任务(task): 在cgroups中,task就是一个进程或线程。
- 控制组(control group): cgroups的资源控制是以cgroup的方式实现,cgroup指明了资源的配额限制。进程可以加入到某个cgroup,也可以迁移到另一个cgroup。
- 层级(hierarchy): cgroup有层级关系,类似树的结构,子节点的cgroup继承父cgroup的属性(资源配额、限制等)。
- 子系统(subsystem): 一个subsystem其实就是一种资源的控制器,比如memory subsystem可以控制进程内存的使用。subsystem需要加入到某个hierarchy,然后该hierarchy的所有cgroup,均受到这个subsystem的控制。
subsystem的类别:
- cpu: 限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset: 为cgroups中的进程分配单独的cpu节点或者内存节点。
- memory: 限制进程的memory使用量。
- blkio: 限制进程的块设备io。
- devices: 控制进程能够访问某些设备。
- net_cls: 标记cgroups中进程的网络数据包,然后可以使用tc模块(traffic control)对数据包进行控制。
- net_prio: 限制进程网络流量的优先级。
- huge_tlb: 限制HugeTLB的使用。
- freezer:挂起或者恢复cgroups中的进程。
- ns: 控制cgroups中的进程使用不同的namespace。
也就是说,cgroup是管理一组task的基本单元,其作为结点组成的树结构叫做hiierarchy。subsystem附加在hierarchy上,对其中的cgroup进行资源限制,同时子结点继承父结点的配置。

三个组件的关系:系统创建新的hierarchy后,系统中的所有进程都会加入这个hierarchy的cgroup根节点,这个根节点是由hierarchy默认创建的。一个subsystem只能附加到一个hierarchy上面,一个hierarchy可以附加多个subsystem,一个进程可以作为多个cgroup的成员,但这些cgroup必须在不同的hierarchy中;一个进程fork出子进程时,父子同属于一个cgroup,但也可以根据需要移到不同的cgroup中。
如何调用内核才能配置Cgroups呢?前面提到,hierarchy是一种树状的组织结构,kernel为了使对Cgroups的配置更加直观,是通过一个虚拟的树状文件系统来配置Cgroup的,也就是通过层级的目录来虚拟出一棵hierarchy(cgroup tree)。示例:
mkdir cgroup-test
sudo mount -t cgroup -o none, name=cgroup-test cgroup-test ./cgroup-test
ls ./cgroup-test
以上在当前目录创建一个文件夹,并挂载了一个cgroup类型的文件系统,这样就创建了一棵hierarchy。ls查看一下目录,会发现生成了一些默认的文件:
cgroup.clone_children cpuset的subsystem会读取这个配置文件,如果这个值(默认值是0)是 1 子cgroup才会继承父cgroup的cpuset的配置
cgroup.procs是树中当前节点cgroup中的进程组ID,现在的位置是根节点,这个文件中会有现在系统中所有进程组的ID
notify_on_release和release_agent 会一起使用。notify_on_release 标志当这个cgroup最后一个进程退出的时候是否执行了release_agent
release_agent 则是一个路径,通常用作进程退出后自动清理不再使用的cgroup
task 标识该cgroup下面进程ID,如果把一个进程ID写到task文件中,便会把相应的进程加入到这个cgroup中。
在该目录下继续创建文件夹,就是扩展子cgroup,其也会自动创建一些文件配置项。
但是由于我们创建的这个hierarchy没有附加任何subsystem(-o 后的值为none),所以没办法对其中的cgroup限制进程资源占用。值得一提的是,各种subsystem在/sys/fs/cgroup/下有系统已经创建好的默认的hierarchy,因而很方便我们使用。(或者也可以使用-o memory)
在/sys/fs/cgroup/memory下:
sudo mkdir test && cd test
sudo sh -c “echo “100m” > memory.limit_in_bytes”
sudo sh -c “echo $$ > tasks”
stress –vm-bytes 200m –vm-keep -m 1
以上,我们在挂载了memory子系统的hierarchy下创建了一个cgroup,并通过修改配置项对其内存资源限制(200m以下),然后使用stress进行压力测试。
使用top等命令可以发现,其内存确实被限制,验证了cgroups的限制资源的能力。
在Docker中,我们可以在启动一个容器的时候传入参数-m 100m达到这种效果,即将容器的内存占用限制在100m,这背后就是由cgroups技术实现的。Dokcer通过为每个容器创建cgroup,配置资源限制和监控。
Union File System
Union FS,是一种为linux,fressBSD,netBSD操作系统设计的,把其他文件系统联合到一个联合挂载点的文件系统服务。它使用branch把不同文件系统的文件和目录透明地覆盖,形成一个单一的文件系统。这些branch或者是ro的,或者是rw的,所以当对这个虚拟后的联合文件系统进行写操作时,系统是真正写到了一个新文件中。看起来这个虚拟后的联合文件系统可以对任何文件进行操作,但其实并没有改变原来的文件,这是因为unionfs使用了一个重要的资源管理技术——写时复制(copy-on-write)。
coW,也叫做隐式共享,是一种对可修改资源实现高效复制的资源管理技术。它的思想是,如果一个资源是重复的,但没有任何修改,这时不需要立即创建一个新的资源,这个资源可以被新旧实例共享。创建新资源只会发生在第一次写操作,也就是对资源进行修改的时候。通过这种资源共享的方式,可以显著减少未修改资源的复制所带来的消耗。
AUFS
AUFS,全称是Advanced Multi-Layerd Unification Filesystem,完全重写了早期的UnionFS 1.x,并引入了一些新的功能,比如可写分支的负载均衡。
AUFS是docker选用的第一种存储驱动,具有快速启动容器、高效利用存储和内存等优点,直到现在依然被docker支持。接下来,介绍docker是如何利用AUFS存储镜像和容器的。
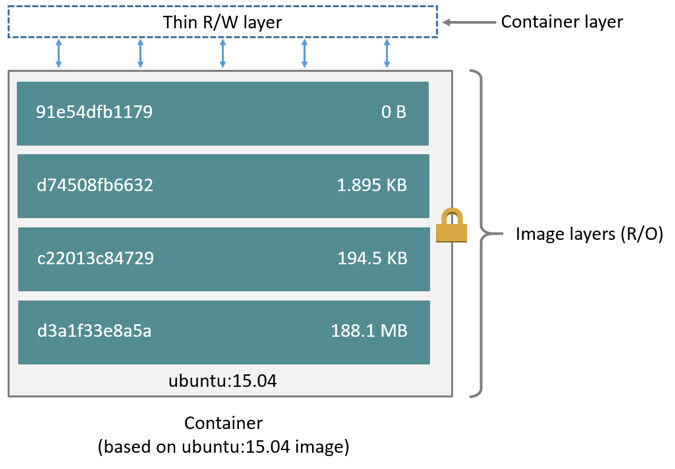
我们知道,在docker中,每一个image都是由一系列read-only layer组成的。image layer的内容都存储在/var/lib/docker/aufs/diff目录下。而/var/lib/docker/aufs/layers目录则存储image layer如何堆栈这些layer的metadata。
Overlay2
Overlay2是现版本Docker默认使用的存储驱动,通常情况下,overlay2 会比AUFS性能更好,而且更加稳定,但是二者基本的存储思路都是分层。overlay2 和 AUFS 类似,它将所有目录称之为层(layer),overlay2 的目录是镜像和容器分层的基础,而把这些层统一展现到同一的目录下的过程称为联合挂载(union mount)。overlay2 把目录的下一层叫作lowerdir,上一层叫作upperdir,联合挂载后的结果叫作merged。
总体来说,overlay2 是这样储存文件的:overlay2将镜像层和容器层都放在单独的目录,并且有唯一 ID,每一层仅存储发生变化的文件,最终使用联合挂载技术将容器层和镜像层的所有文件统一挂载到容器中,使得容器中看到完整的系统文件。
接下来以overlay2为例,探究docker是如何存放镜像的。
首先从仓库拉取一个ubuntu16.04镜像,然后查看该镜像的信息:
docker pull ubuntu:16.04
观察到如下信息:
16.04: Pulling from library/ubuntu
58690f9b18fc: Pull complete
b51569e7c507: Pull complete
da8ef40b9eca: Pull complete
fb15d46c38dc: Pull complete
Digest: sha256:0f71fa8d4d2d4292c3c617fda2b36f6dabe5c8b6e34c3dc5b0d17d4e704bd39c
Status: Downloaded newer image for ubuntu:16.04
可以看到,镜像正是被分为4层拉取下来的。在/var/lib/docker/overlay2可以找到所有拉取下来的layer。此外,该目录下还有一个l目录,这里全是到各层diff之间的软链接,把一些较短的随机串软连到镜像层的 diff 文件夹下,这样做是为了避免达到mount命令参数的长度限制。
先随意查看一个镜像层的内容:diff,link,lower,work。
在这里,link 文件内容为该镜像层对应l目录中的短 ID,diff 文件夹为该镜像层的改动内容,也是被联合挂载的内容,lower 文件为该层的所有父层镜像的短 ID,规定了镜像间的层序关系。
我们可以用docker inspect来找到某个镜像的层级之间的关系:
docker image inspect ubuntu
...
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/ca36b188418e7d85232c6d90144380e543ec45fb4cc962bf2f45d4a823c0f9cd/diff:/var/lib/docker/overlay2/4f934d2bbd300caf92c0f00c85201053c20881c91810f32c5bef850581990acd/diff:/var/lib/docker/overlay2/579a385ff86c563d0c4c71bcc5471133b674d102de7ab38555e66ec955f5dcdb/diff",
"MergedDir": "/var/lib/docker/overlay2/aac78f83be662b8ec26fadd30aff555f35f66453b834a1d71edd7aea83607b40/merged",
"UpperDir": "/var/lib/docker/overlay2/aac78f83be662b8ec26fadd30aff555f35f66453b834a1d71edd7aea83607b40/diff",
"WorkDir": "/var/lib/docker/overlay2/aac78f83be662b8ec26fadd30aff555f35f66453b834a1d71edd7aea83607b40/work"
},
"Name": "overlay2"
},
...
其中 MergedDir 代表当前镜像层在 overlay2 存储下的目录,LowerDir 代表当前镜像的父层关系,使用冒号分隔,冒号最后代表该镜像的最底层。
接着启动容器,再用docker inspect查看容器的层级关系:
docker inspect ubuntu
...
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/f5de3e3e085c8c0a6591705d368523927ba6e3fd5434ba802a3315d6747ce00d-init/diff:/var/lib/docker/overlay2/aac78f83be662b8ec26fadd30aff555f35f66453b834a1d71edd7aea83607b40/diff:/var/lib/docker/overlay2/ca36b188418e7d85232c6d90144380e543ec45fb4cc962bf2f45d4a823c0f9cd/diff:/var/lib/docker/overlay2/4f934d2bbd300caf92c0f00c85201053c20881c91810f32c5bef850581990acd/diff:/var/lib/docker/overlay2/579a385ff86c563d0c4c71bcc5471133b674d102de7ab38555e66ec955f5dcdb/diff",
"MergedDir": "/var/lib/docker/overlay2/f5de3e3e085c8c0a6591705d368523927ba6e3fd5434ba802a3315d6747ce00d/merged",
"UpperDir": "/var/lib/docker/overlay2/f5de3e3e085c8c0a6591705d368523927ba6e3fd5434ba802a3315d6747ce00d/diff",
"WorkDir": "/var/lib/docker/overlay2/f5de3e3e085c8c0a6591705d368523927ba6e3fd5434ba802a3315d6747ce00d/work"
},
"Name": "overlay2"
},
...
这里MergedDir 的内容即为容器层的工作目录,LowerDir 为容器所依赖的镜像层目录。实际上,overlay2将lowerdir、upperdir、workdir联合挂载,形成最终的merged挂载点,其中lowerdir是镜像只读层,upperdir是容器可读可写层,workdir是执行涉及修改lowerdir执行copy_up操作的中转层(例如,upperdir中不存在,需要从lowerdir中进行复制,该过程暂未详细了解,遇到了再分析)。
实战:自制简单docker
明白了以上三个基本原理,实际上我们已经可以制作一个简单的小docker了!这里为了方便,还是使用AUFS作为存储。
首先,使用go的urfave/cli命令行工具,将代码改造成命令行程序:
const usage = `we make a small docker container by ourselves using basic knowledge.`
func main() {
app := cli.NewApp()
app.Name = "mydocker"
app.Usage = usage
app.Commands = []cli.Command{
initCommand,
runCommand,
}
app.Before = func(context *cli.Context) error {
// Log as JSON instead of the default ASCII formatter.
log.SetFormatter(&log.JSONFormatter{})
log.SetOutput(os.Stdout)
return nil
}
if err := app.Run(os.Args); err != nil {
log.Fatal(err)
}
}
这里我们规定了2条命令:run和init,其中run就和docker run一样是启动容器,而init是内部调用的用于初始化容器的命令。接着,我们详细定义这两条命令:
var runCommand = cli.Command{
Name: "run",
Usage: `Create a container with namespace and cgroups limit
mydocker run -ti [command]`,
Flags: []cli.Flag{
cli.BoolFlag{
Name: "ti",
Usage: "enable tty",
},
},
Action: func(context *cli.Context) error {
if len(context.Args()) < 1 {
return fmt.Errorf("Missing container command")
}
var cmdArray []string
for _, arg := range context.Args() {
cmdArray = append(cmdArray, arg)
}
tty := context.Bool("ti")
Run(tty, cmdArray)
return nil
},
}
var initCommand = cli.Command{
Name: "init",
Usage: "Init container process run user's process in container. Do not call it outside",
Action: func(context *cli.Context) error {
log.Infof("init come on")
err := container.RunContainerInitProcess()
return err
},
}
其中flags规定了一些调用参数,如ti就和docker中一样,意义是启动终端和交互。action是命令真正的入口,这里先判断有无命令,再读取args将命令存入cmdArray。最后调用了Run函数:
func Run(tty bool, comArray []string) {
parent, writePipe := container.NewParentProcess(tty)
if parent == nil {
log.Errorf("New parent process error")
return
}
if err := parent.Start(); err != nil {
log.Error(err)
}
sendInitCommand(comArray, writePipe)
parent.Wait()
mntURL := "/cproot/mnt/"
rootURL := "/cproot/"
container.DeleteWorkSpace(rootURL, mntURL)
os.Exit(0)
}
func sendInitCommand(comArray []string, writePipe *os.File) {
command := strings.Join(comArray, " ")
log.Infof("command all is %s", command)
writePipe.WriteString(command)
writePipe.Close()
}
接着,首先调用了NewParentProcess函数,如下:
func NewParentProcess(tty bool) (*exec.Cmd, *os.File) {
readPipe, writePipe, err := NewPipe()
if err != nil {
log.Errorf("New pipe error %v", err)
return nil, nil
}
cmd := exec.Command("/proc/self/exe", "init")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWNET | syscall.CLONE_NEWIPC,
}
if tty {
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}
cmd.ExtraFiles = []*os.File{readPipe}
mntURL := "/cproot/mnt/"
rootURL := "/cproot/"
NewWorkSpace(rootURL, mntURL)
cmd.Dir = mntURL
return cmd, writePipe
}
func NewPipe() (*os.File, *os.File, error) {
read, write, err := os.Pipe()
if err != nil {
return nil, nil, err
}
return read, write, nil
}
这里先调用NewPipe创建了用于外部和容器通信的管道,接着设置了需要执行的两条命令:
/proc/self/exe 当前正在运行的进程本身的可执行文件,这就是自己调用自己,来初始化刚创建出的进程。
init 就是刚刚自定义的命令。
接着设置了系统调用属性:这里就是fork出一个新进程,且为这个进程设置了若干namespace,来与外部环境进行隔离。
由于进程的3个文件描述符已经被标准输入、输出、错误所占用,所以就通过extraFiles传入了管道读取端给子进程。接着规定了,联合文件系统最终的挂载目录和镜像、容器layer所在的目录。紧接着便调用了NewWorkSpace函数:
func NewWorkSpace(rootURL string, mntURL string) {
CreateReadOnlyLayer(rootURL)
CreateWriteLayer(rootURL)
CreateMountPoint(rootURL, mntURL)
}
func CreateReadOnlyLayer(rootURL string) {
busyboxURL := rootURL + "busybox/"
busyboxTarURL := rootURL + "busybox.tar"
exist, err := PathExists(busyboxURL)
if err != nil {
log.Infof("Fail to judge whether dir %s exists. %v", busyboxURL, err)
}
if exist == false {
if err := os.Mkdir(busyboxURL, 0777); err != nil {
log.Errorf("Mkdir dir %s error. %v", busyboxURL, err)
}
if _, err := exec.Command("tar", "-xvf", busyboxTarURL, "-C", busyboxURL).CombinedOutput(); err != nil {
log.Errorf("Untar dir %s error %v", busyboxURL, err)
}
}
}
func CreateWriteLayer(rootURL string) {
writeURL := rootURL + "writeLayer/"
if err := os.Mkdir(writeURL, 0777); err != nil {
log.Errorf("Mkdir dir %s error. %v", writeURL, err)
}
}
func CreateMountPoint(rootURL string, mntURL string) {
if err := os.Mkdir(mntURL, 0777); err != nil {
log.Errorf("Mkdir dir %s error. %v", mntURL, err)
}
dirs := "dirs=" + rootURL + "writeLayer:" + rootURL + "busybox"
cmd := exec.Command("mount", "-t", "aufs", "-o", dirs, "none", mntURL)
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Errorf("%v", err)
}
}
这个函数分为3个部分,首先是创建镜像层(只读),接着是创建容器可写层,最后就是用AUFS的方式将容器层、可写层联合挂载到指定的mntURL下。
通过调用newparentprocess,我们就从返回值得到了这样的一条命令,并在Run函数中对其调用start函数,这才是真正开始这条命令的执行,它会首先clone出一个namespace隔离的进程,并在子进程中先调用/proc/self/exe,即其本身,接着调用我们写的init方法,进行初始化。然后便开始执行sendInitCommand函数,即将用户输入的命令读取到管道的写入端。当程序执行完毕后,会调用wait释放进程资源并退出,以及执行DeleteWorkSpace删除可写层和解挂aufs系统(相当于退出容器),这些都是后话。
生成子进程后,首先会调用自己,即启动子进程。接着子进程就会执行init命令,调用RunContainerInitProcess()。也就是说,调用这个函数时,我们已经身处namespace内的子进程了:
func RunContainerInitProcess() error {
cmdArray := readUserCommand()
if cmdArray == nil || len(cmdArray) == 0 {
return fmt.Errorf("Run container get user command error, cmdArray is nil")
}
setUpMount()
path, err := exec.LookPath(cmdArray[0])
if err != nil {
log.Errorf("Exec loop path error %v", err)
return err
}
log.Infof("Find path %s", path)
if err := syscall.Exec(path, cmdArray[0:], os.Environ()); err != nil {
log.Errorf(err.Error())
}
return nil
}
func readUserCommand() []string {
pipe := os.NewFile(uintptr(3), "pipe")
msg, err := ioutil.ReadAll(pipe)
if err != nil {
log.Errorf("init read pipe error %v", err)
return nil
}
msgStr := string(msg)
return strings.Split(msgStr, " ")
}
/**
Init 挂载点
*/
func setUpMount() {
pwd, err := os.Getwd()
if err != nil {
log.Errorf("Get current location error %v", err)
return
}
log.Infof("Current location is %s", pwd)
pivotRoot(pwd)
//mount proc
defaultMountFlags := syscall.MS_NOEXEC | syscall.MS_NOSUID | syscall.MS_NODEV
quarantineMountFlags := syscall.MS_PRIVATE | syscall.MS_REC
syscall.Mount("","/","", uintptr(quarantineMountFlags), "")
syscall.Mount("proc", "/proc", "proc", uintptr(defaultMountFlags), "")
//syscall.Mount("tmpfs", "/dev", "tmpfs", syscall.MS_NOSUID|syscall.MS_STRICTATIME, "mode=755")
}
func pivotRoot(root string) error {
/**
为了使当前root的老 root 和新 root 不在同一个文件系统下,我们把root重新mount了一次
bind mount是把相同的内容换了一个挂载点的挂载方法
*/
log.Infof("pivotroot: root is %s", root)
if err := syscall.Mount(root, root, "bind", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return fmt.Errorf("Mount rootfs to itself error: %v", err)
}
// 创建 rootfs/.pivot_root 存储 old_root
pivotDir := filepath.Join(root, ".pivot_root")
if err := os.Mkdir(pivotDir, 0777); err != nil {
return err
}
// pivot_root 到新的rootfs, 现在老的 old_root 是挂载在rootfs/.pivot_root
// 挂载点现在依然可以在mount命令中看到
if err := syscall.PivotRoot(root, pivotDir); err != nil {
return fmt.Errorf("pivot_root %v", err)
}
// 修改当前的工作目录到根目录
if err := syscall.Chdir("/"); err != nil {
return fmt.Errorf("chdir / %v", err)
}
pivotDir = filepath.Join("/", ".pivot_root")
// umount rootfs/.pivot_root
if err := syscall.Unmount(pivotDir, syscall.MNT_DETACH); err != nil {
return fmt.Errorf("unmount pivot_root dir %v", err)
}
// 删除临时文件夹
return os.Remove(pivotDir)
}
首先是调用readCommand从管道读取用户传入的命令,并在后来识别系统环境变量并予以执行。接着调用setupMount开始一系列挂载工作。这里读取到的pwd就是指定的mntURL,也就是联合文件系统的挂载点,容器的工作目录。接着,调用pivotRoot(pwd)。众所周知,pivot_root是一个系统调用,主要功能是改变当前的rootfs。pivot_root可以将当前进程的rootfs移动到put_old文件夹,再使new_root成为新的rootfs。new_root和put_old必须不能同时存在当前root的同一个文件系统中。这个系统调用和chroot命令区别在于,前者是将整个系统切换到一个新的root目录,并移除对之前root文件系统的依赖,这样就能umount原先的rootfs。而后者只是针对某个进程,系统的其他部分依旧运行于老的root目录中。
注意!在挂载开始前,我们首先有这样的操作:
quarantineMountFlags := syscall.MS_PRIVATE | syscall.MS_REC
syscall.Mount("","/","", uintptr(quarantineMountFlags), "")
这就是开始将mount namespace时提出的,其作用相当于mount –make-rprivate /,即递归修改整个mount树的propagate type为private,这样我们在容器内的挂载操作才不会传给外部。否则在接下来挂载proc后,回到主机系统,会发现很多命令都无法使用了。这其实就是因为主机的proc被修改了,需要在主机重新mount一次proc才能恢复正常。
这之后,init命令的工作也就做完了,此时我们的容器已启动起来。