此为旧博客补档,原文上传于2022年7月5日。
背景
自从AlexNet以来,人们一直致力于探索更深的神经网络,以更好地解决计算机视觉等领域的问题。从2012年到2014年,ILSVRC大赛的优胜者一直在增加网络的深度。更多的卷积层可以使得提取的特征更加丰富,但同时也会带来梯度消失/爆炸和过拟合的问题,导致模型不收敛。虽然当时大牛们已经提出了诸如Batch Normalization的方法解决这些问题,但人们依然发现一个奇怪的现象:随着网络深度的不断增加,网络预测准确度先逐渐增大趋于饱和,最后反而将重新开始下降!并且这还并不是过拟合导致的结果,因为误差依然在增大。这似乎是相当反常识的一个现象,因为只要我们让更深的网络层采取恒等映射,理论上就能保证网络性能至少不会比浅层神经网络下降,而对于能模拟几乎任何映射的神经网络来说,恒等映射简直是小菜一碟。由此可见,是神经网络背后隐藏的学习思路出现了问题,比如更深处的多个网络层的堆叠因为非线性变化的大量使用,连恒等映射都无法学习了。
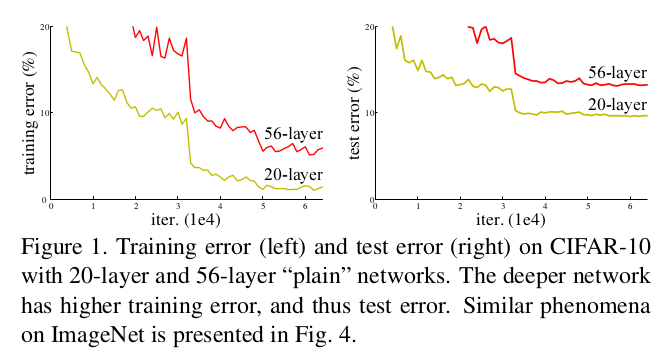
何恺明大佬将这个现象称为“退化”(degradation),并提出了一种全新的网络结构以解决退化问题,使得神经网络能继续从提高深度获得准确度的收益。这就是“残差网络”(ResNet)的诞生。
残差单元的原理
ResNet的设计核心思想正是受到了退化现象的启发。与其学习目标映射$H(x)$,转而学习映射的残差$F(x)=H(x)- x$,进而原先的映射可以表示为$F(x)+x$。残差的获取是通过短路连接实现。
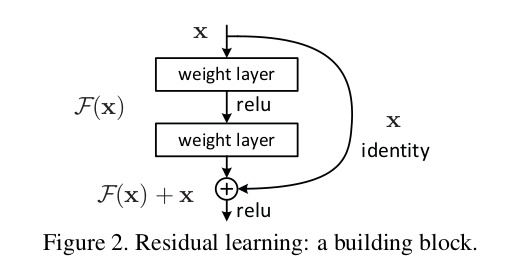
为什么这样以来就能避免退化了呢?我尝试从数学上进行了推导:
首先,对于一个图2所示的残差单元,假设其输入为$x$,输出为$y$,$F(x)$是学习得到的残差,并且$F(x)$和$x$具有相同的维度,则有
$$
y = F(x) + x
$$
若省略bias,并令$\sigma$表示ReLU,W1, W2分别表示两个weight layer(可以是卷积或全连接)的权值,则$F(x)$又可写成:
$$
F(x) = W_2\sigma(W_1x)
$$
进而,y可表示为:
$$
y = W_2\sigma(W_1x) + x
$$
如果我们堆叠多个这样的残差单元,并令$x_i$表示为第i个残差单元的输入,同时也是第(i-1)个残差单元的输出,那么上式可以改写为如下形式:
$$
x_{i+1} = W_2\sigma(W_1x_i) + x_i
$$
则从第a个残差单元开始,到第b个残差单元结束,这样一组残差单元整体端到端的输入输出关系可由累加得到:
$$
x_{b+1} = \sum_{i=a}^b W_{2i}\sigma(W_{1i}x_i) + x_a
$$
更明确地写,将$x_{b+1}$换为$y_b$,则最终得到第b个残差单元的输出和第a个残差单元的输入间的关系为:
$$
y_b = \sum_{i=a}^b W_{2i}\sigma(W_{1i}x_i) + x_a
$$
接下类就可以利用链式法则,求得反向传播到第a层的梯度:
$$
\frac{\partial loss}{\partial x_a} = \frac{\partial loss}{\partial y_b} \frac{\partial y_b}{\partial x_a} = \frac{\partial loss}{\partial y_b}(1 + \frac{\partial}{\partial x_i}\sum_{i=a}^b W_{2i}\sigma(W_{1i}x_i))
$$
上式说明,在进行反向传播时,首先括号中的第二项十分容易计算,此外由于括号中”1”这一项的存在,除非第二项为-1,否则是不会发生梯度消失的,而第二项求和为-1附近值的概率是极小的,即能实现梯度的无损传播,完美规避了传统DNN的弊端。
网络结构与PyTorch源码阅读
笔者在此先偷了个懒,因为光看论文没有太搞明白,于是先大致阅读了ResNet在torchvision.models中的实现,自己手撸的轮子版本就下次一定了!下面以resnet34为例,开始分析其源码。
首先从论文中可以找到resnet34的结构示意图:
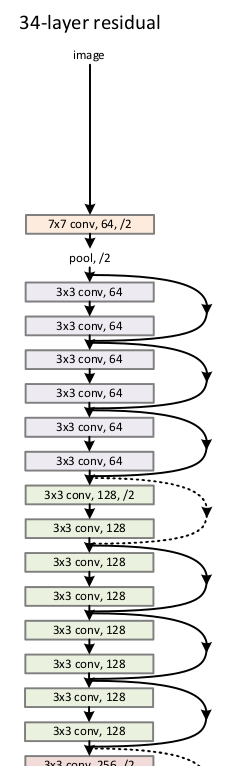
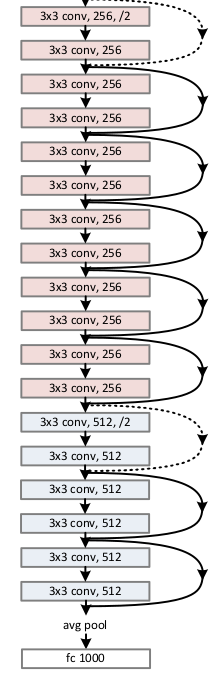
可以看到通过引入残差单元,可以把网络做的很深。
在resnet34中,网络可以分为开头的一层卷积+池化,中间4组不同深度的残差单元,和最终的均值池化与分类器。
当调用resnet34时,实际上是返回了一个内部的_resnet:
1 | def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet: |
注意这里传入的BasicBlock,实际上就是上文中的残差单元:
1 | # 网络定义 |
而传入_resnet的第三个参数,一个int列表,稍后可以看到是指定了各组残差单元中包括的残差单元个数,可以由结构图验证。
再看_resnet内部,实际上就是调用了真正的Resnet:
1 | def _resnet( |
进入ResNet,我们就能真正看到它的结构了:
1 | self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, |
可以看到,以上代码与结构图遥相呼应,其中layer1~4对应4个残差单元组。那么可想而知_makelayer的作用正是根据传入的模块结构,通道数和模块数构建网络层了:
1 | def _make_layer(self, block: Type[Union[BasicBlock, Bottleneck]], planes: int, blocks: int, |
小结
AlexNet的横空出世,开创了DNN在CV中应用的热潮;VGG在AlexNet的基础上,做到了更深的深度;GoogleNet创新性地提出Inception模块和1x1卷积在数据降维中的应用;ResNet解决了前面网络都无从对策的退化问题,开辟了DNN的深度新的上限……现在,各种网络层出不穷,但这些经典网络可以说是奠定了它们共同的坚实基础,因此很有学习和掌握的必要。
至此,这四种网络的基础知识就学习完毕了。接下来,我希望复习几种目标检测中常用的算法(RCNN, Fast-RCNN, Faster-RCNN, YOLO, SSD),以巩固自己的知识,并为项目积累经验。