此为旧博客补档,原文上传于2022年7月4日。
前言
用英文写了前两篇笔记,主要是为了契合周报,但相对于读者可能不太友好,于是从这一篇开始还是用中文做笔记了。这次带来的是对GoogleNet V1的主要结构复现。
背景
上一篇笔记中我们复现的经典网络是VGGNet,它是2014年ImageNet大赛的第二名,而当年的第一名正是GoogleNet。如果说VGG只是对AlexNet的结构作改进,那么GoogleNet则是针对当时DNN设计的痛点做出了许多创新,提出了行之有效的解决方案。随着网络长宽的不断增大和深度的不断加深,其准确度会相应不断提升,但同时参数也在急剧增多,过拟合发生的可能性也越来越大。 当时,一般的DNN的构建思路如下:堆叠卷积层,间以池化层,并通过LRN,Dropout等技巧防止过拟合。然而对于稍深的DNN,对硬件的要求依然很高,问题没有很好地解决。比如VGG相对于AlexNet,换用了更小的卷积核,参数数量固然减少了,但基数依然很大。即便放到现在,笔者笔记本搭载的 RTX2060 也只能保证训练 VGG11(batch_size为32) 而不显存溢出,并且针对一个具有以万为单位的中型数据集能保证一、两个小时完成训练。
对此,GoogleNet主要提出了两点新的加快训练速度和减少参数数量的方案:
- 利用 1x1卷积核(Network in Network)对数据降维,同时增加非线性,并做到减少参数和防止过拟合。
- 提出Inception模块,可以理解为对相似尺度的特征提取的卷积核分组,将大的不利计算的稀疏矩阵转化为多个小的便于计算的密集矩阵,并且结合了1x1卷积核降维处理。Inception的灵感来自Hebbian principle,即如果两个神经元常常同时产生动作电位,这两个神经元之间的连接就会变强,反之则变弱。
网络结构
GoogleNet中主要涉及到3个网络结构:Inception Module,和Auxiliary Classifier,以及最终的GoogleNet主干网络。
Inception Module
直观来看,Inception其实就是将多个卷积和池化的操作放在一起组装为一个小型网络模块,使得神经网络的设计模块化。下图是Inception模块的结构:
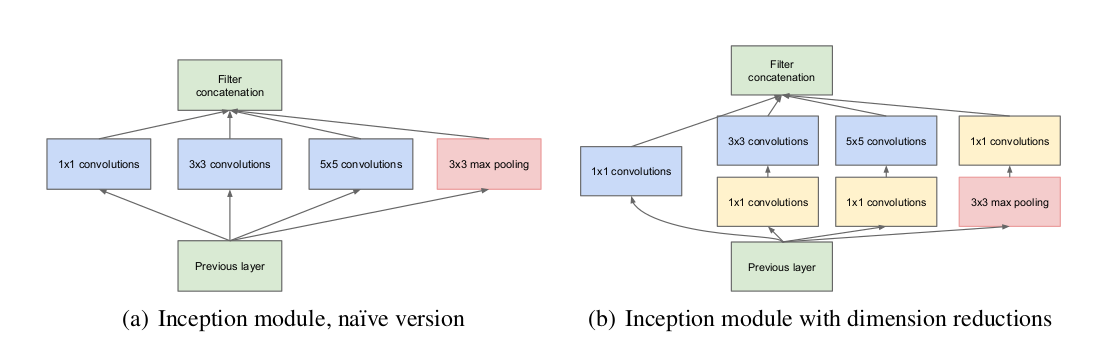
从图中可见,Inception包含了一组不同卷积核大小的卷积核和一个必要的均值池化层。不同尺度的特征,往往需要不同大小的感受野来捕获。传统的网络结构中,在一层卷积层只能有一种大小卷积核,其能获得的特征不一定是最佳的,而可能需要别的大小的卷积核。Inception所做的正是将这一过程交给神经网络判断,网络通过调节参数,自主选择合适大小的卷积核。原始的Inception结构如图(a)所示,这样的结构仍会带来较多参数,不能直接用于网络。解决方案是加入先前所述的1x1卷积核,做到数据降维,减少参数数量,于是最终形成了图(b)所示的结构。
用Pytorch实现如下:
1 | class Inception(nn.Module): |
Auxiliary Classifier
Auxiliary Classifier,即辅助分类器,是为了增强梯度(防止出现梯度消失),以及增加正则化而设计的一种子模块网络。它只在训练过程加入,其运算结果在乘以一个权重系数(0.3)后与最终输出结果一起作用于反向传播。它由一个均值池化层,一个1x1卷积+ReLU激活层,一个全连接层,一个Dropout层,和一个接了softmax的全连接层构成。
用pytorch实现如下:
1 | class AuxClassifier(nn.Module): |
GoogleNet
GoogleNet的结构如下:
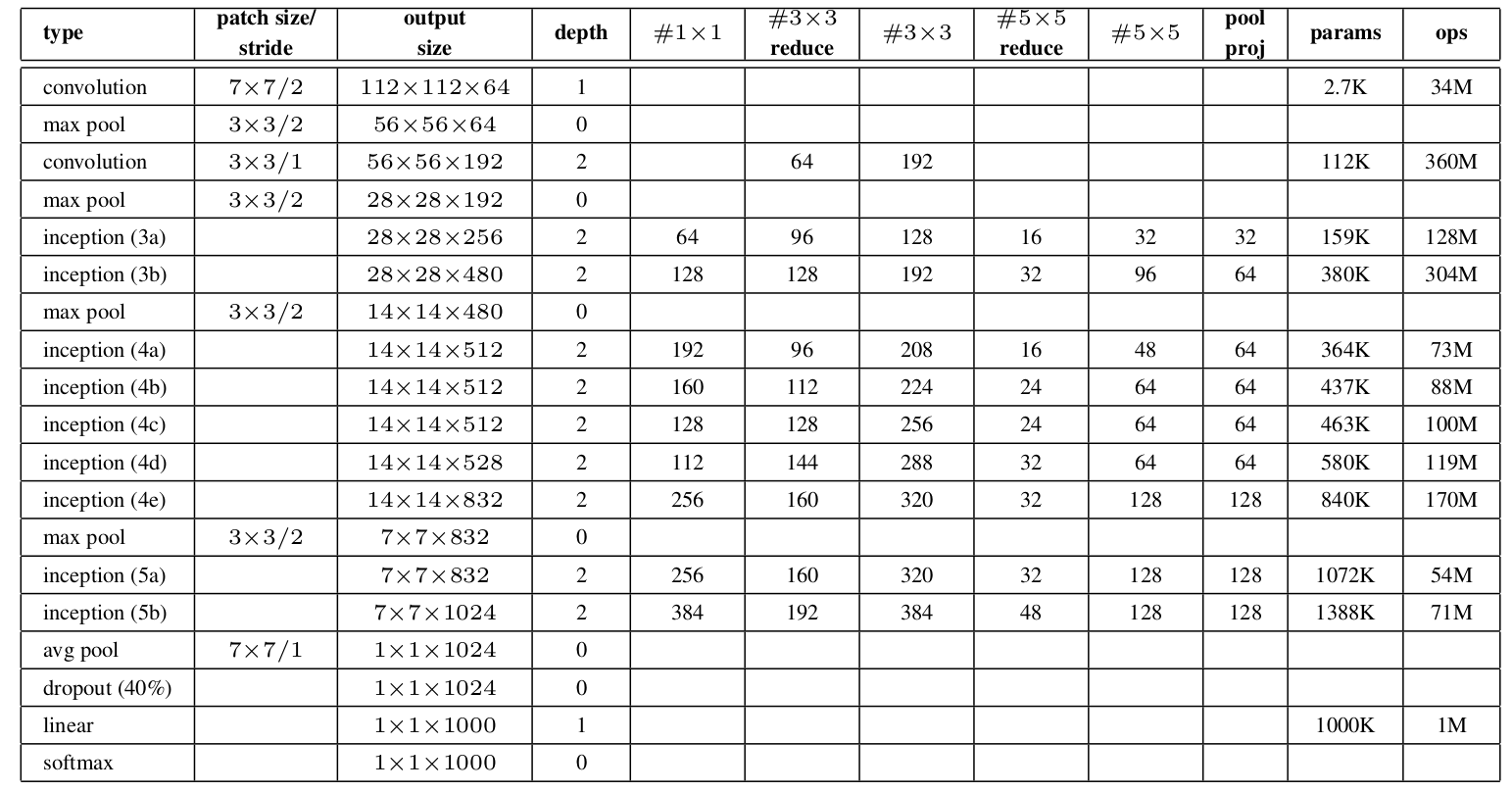
可见,在较浅层,主要组成部分依然是传统的卷积+池化。随后便是Inception模块的不断堆叠,间以最大池化,最后是dropout+全连接层输出分类结果。需要注意的是这里的全连接层实际上是一个均值池化层,通过7x7的滤波器大小,将前一层输入的7x7大小的特征直接转化为1x1。论文提到这里用池化层代替卷积层,实现了0.6%的准确度提升。
用pytorch实现如下:
1 | class GoogleNet(nn.Module): |
注意这里我们和之前一样,用较小的数据集代替ImageNet,并对网络中输出层做相应调整。
训练
设置batch_size为32,经过20个epoch,得到训练结果如下:
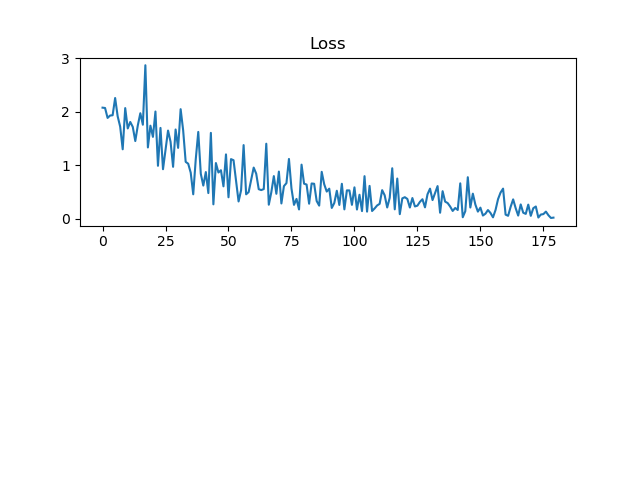
loss图像:
accuracy图像:
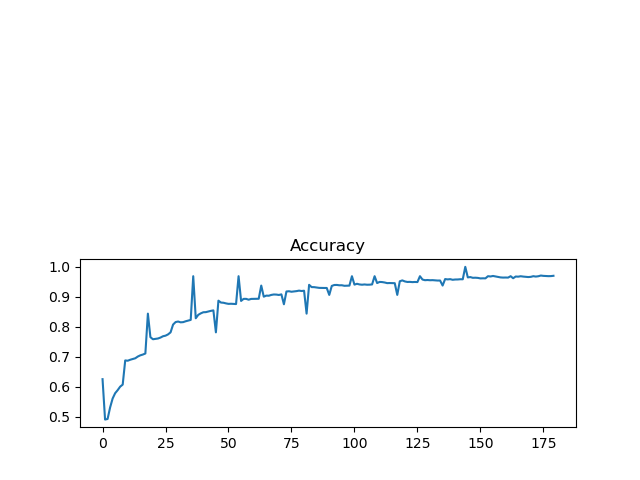
这里依然出现了之前一样的问题:loss曲线剧烈抖动,同时accuracy每轮epoch开始有毛刺?新手上路,实在没弄清楚原因。虽然图像不甚完美,但可看到loss还是随训练总体上是降低的,而accuracy是升高的。并且在验证集中也能达到准确率目标。
结论
GoogleNet作为一种经典DNN,还有许多值得学习的设计思想,并且其本身也经过了多次迭代升级,这里仅仅是对初代GoogleNet(V1)进行了Pytorch的代码复现。
下一个学习目标定为ResNet的论文阅读和pytorch复现。